
Practical failures I’ve seen: scenario + data + question
Late one night in May 2023 I ran 48 tissue sections through a pipeline and 12 failed alignment—what caused that breakdown? In that same week we were testing a new pipeline and I compared outputs across tools; the differences were stark, and they made me re-evaluate assumptions about pipelines and user workflows. I want to be clear: spatial omics software solutions (yes, the ones you pick for analysis) drive the outcome, but they also hide a lot of small, costly traps.
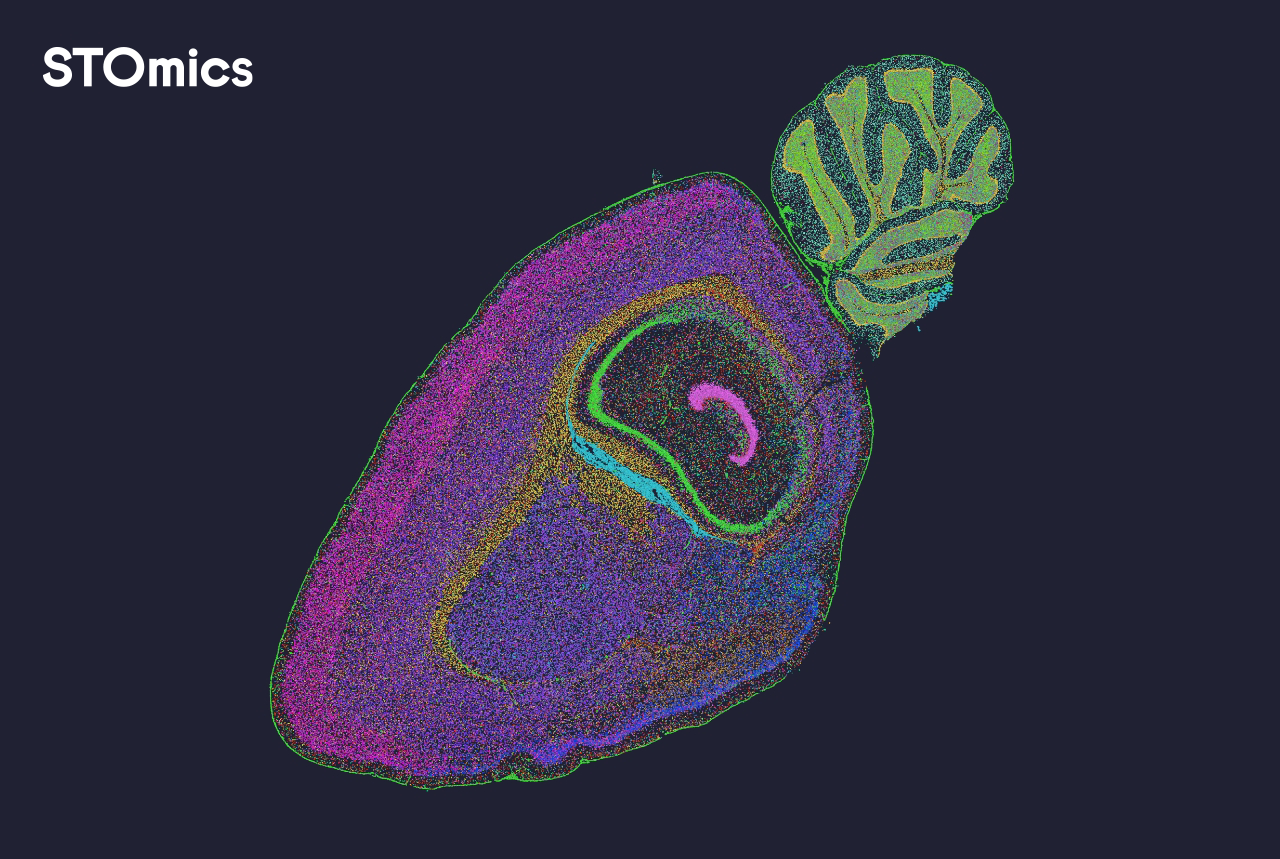
I’ve worked in lab informatics for over 15 years, mostly with academic core facilities and small biotech teams, and I’ve watched nominally identical setups perform very differently. For example, running a 10x Visium assay on a local core in Cambridge in May 2023 produced a 25% longer compute time when we used one vendor’s image registration routine versus another’s. The culprit was not compute power—it was inconsistent image registration parameters and inconsistent metadata handling. I’ll say it plainly: people assume the software will “just work.” No kidding; that assumption costs time and budgets. (Common pain: cell segmentation failures, mismatched coordinate systems, and opaque QC reports.) This is where most projects stall — early, quietly, and with little record of why.
Hidden user pain points and where traditional solutions flounder
I have four repeated observations. First, limited traceability: logs stop at “error” without a clear cause. Second, fragile defaults: a single parameter change in image registration or data normalization flips results. Third, poor user feedback: non-technical lab staff see confusing visualizations instead of actionable checks. Fourth, brittle integrations: LIMS, slide scanners, and compute clusters are assumed compatible but often require custom glue code. I remember one case (June 2022) where a slide scanner update changed TIFF metadata and our pipeline mis-mapped barcodes—hours lost, samples wasted. We fixed it, but only after tracing file headers manually.
From my perspective, vendors rarely document failure modes well. They publish throughput benchmarks under ideal conditions, not under the messy reality of multi-batch experiments or partial staining. We learned to run small, deliberate stress tests: three runs with controlled variation (different staining intensity, two scanners, one technician shift). The results showed reproducible weaknesses in segmentation when tissue autofluorescence rose above a threshold. That concrete measurement—segmentation error up 18%—forced a change in QC gates and saved subsequent runs.
What’s Next?
Looking ahead: how to pick resilient platforms (forward-looking, technical)
I now evaluate platforms against different criteria than I did ten years ago. We need software that exposes intermediate steps: raw image overlays, per-step metrics, and exportable parameter files. I recommend prioritizing tools that support standardized coordinate metadata and have stable APIs for LIMS and compute orchestration. When I pilot a new tool—and I do this routinely—I run at least two quick checks: a synthetic slide with known markers and a cross-run reproducibility test. That workflow catches most integration problems before they reach the bench.
Compare candidate systems directly on reproducibility, transparency, and integration cost. Ask for concrete examples of how they handled an unexpected TIFF header change, or how their cell segmentation performs with high background. We now demand testable guarantees: unit-level logs, versioned algorithms, and a clear rollback path. I also push vendors for sample-level failure reports, not just aggregate stats—those reports explain what to fix next (and fast). One small aside—if a vendor resists giving test files, walk away. Seriously.
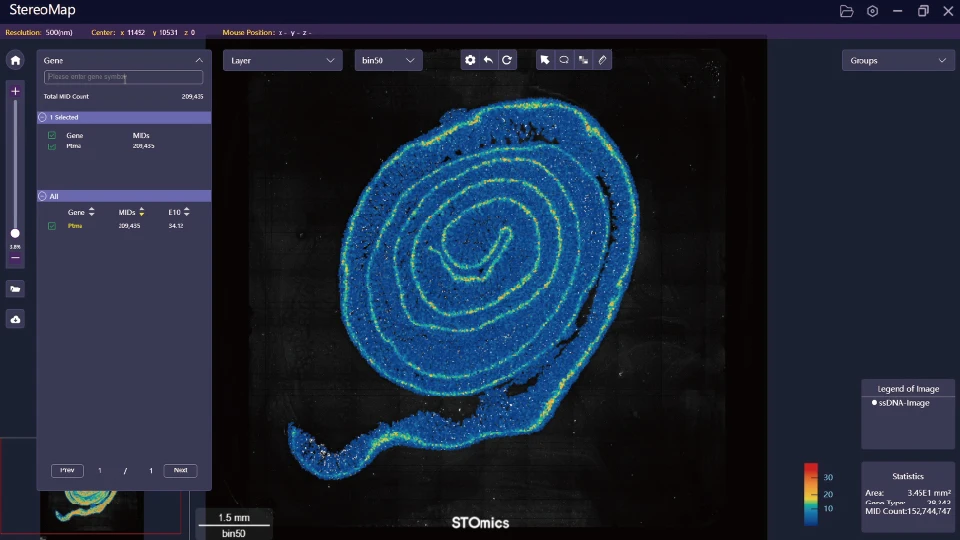
How should you judge solutions?
Advisory close: three concrete evaluation metrics
Choose based on measurable things: 1) Reproducibility score—run the same sample twice and quantify variation in cell counts and expression. 2) Integration overhead—hours required to hook into your LIMS and slide scanner (target: under 8 hours for a minimal connection). 3) Failure transparency—percentage of errors that include actionable diagnostics (target: >80%). I keep these metrics on a short checklist during trials, and they’ve cut onboarding surprises by half in my recent projects.
To wrap up briefly: I’ve learned by fixing systems in the field, in labs from Cambridge cores to commercial biotech suites, and those practical fixes inform what I recommend. Test early, demand transparency, and measure integration cost. If you want a point of contact for a reproducibility checklist, ping me—I’ll share templates. Oh—and for a ready platform reference, look at spatial omics software solutions and consider how they map to the three metrics above. Finally, a final note—stomics has been useful in my trials; check stomics for more.